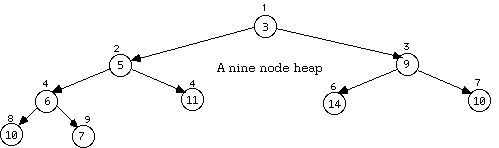
The structure known as a heap is an interesting hybrid. It is most easily conceptualized as a binary tree constructed according to some specific rules on the data being entreed. However, each node of the tree is numbered consecutively, and it is possible to work with a heap by implementing it as an array.
A heap is a sequence of data nodes n1, n2, n3, n4, ... nmax in which ni <= n2i and ni <= n2i+1 for all i with 1 <= i <= max/2.
In a tree implementation, the n2i and n2i+1 are the children of the node ni, (this makes the tree binary) so the rule in the definition can be expressed as:
In a heap every parent is greater than its child.
A reverse heap (in which the rule is "less than the child" could also be constructed, but this will not be done here. In the heap shown below there are nine nodes. The cardinal data at each node is placed inside the circle and each node is numbered outside the node to illustrate the structural relationships.
In order to build a heap, data is placed in the tree as it arrives in the following manner:
Add Heap Data =
add a new node at the next leaf position
use this new node as the current position
While new data is less than that in the parent of the current node
move the parent down to the current node
make the parent (now vacant) the current node
Place data in current node
Thus, new nodes are always added on the deepest level in an orderly way, and the tree never becomes unbalanced. There is no particular relationship among the data items in the nodes on any given level, even the ones that have the same parent, so certainly a heap is not a sorted structure. It can however, be regarded as partially ordered. One should also note that a given set of data can be formed into many different heaps. Which one results from the heapification will depend on the order in which the data arrives.
Example: Data arrives to be heaped in the order 54, 87, 27, 67, 19, 31, 29, 18, 32, 56, 7, 12, 31
The series of diagrams illustrates what the heap looks like as each data item is added.
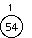
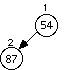
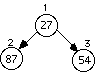
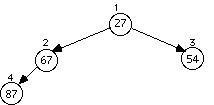
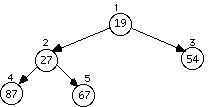
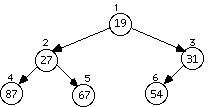
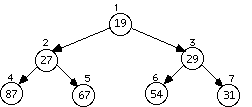
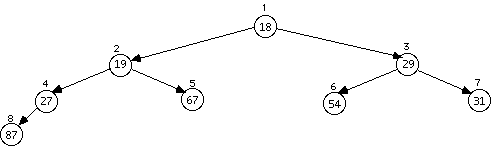
The next two insertions do not cause a rearrangement
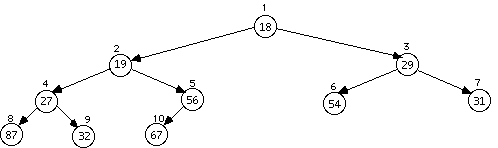
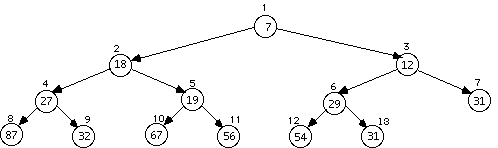
The following two both cause a rearrangement, and the one after that does not.
If deletions of data are to be done, some work may be necessary to restore the tree to the properly filled state, because not all leaves are on the same level. Only if the data in the highest numbered node is deleted will the operation be a simple inverse of insertion, for in that case the node can simply be removed without affecting anything else. If data in some other node is deleted, there are two possible choices for what the algorithm could do:
- mark the node as unused and do the next insert there rather than by generating a new node
- shift data around in the tree so that all the nodes are occupied except the highest numbered one, and then delete that.
The first has the advantage of not requiring the tree to be rearranged, but the disadvantage of making insertion more complicated by requiring a list of unused nodes to be maintained. The second has the advantage that insertion need not be changed, and the advantage of being more symmetric with insertion, but the disadvantage of producing a more complicated deletion algorithm:
Delete and restructure=
save data from last node
If node to delete data from is not last node
insert data from last node starting in node where data is to be deleted
reheapify working up or down as necessary from this point.
delete last node
If duplicate items are allowed, as in the example above, which one gets deleted depends on the order in which the tree is traversed to find the data. If the item 31 is deleted then any forward traversal to do so will find and delete the one on the bottom row. Other sets of rules are possible of course. Adding an item could mean forbidding duplicates. Deleting could mean deleting all items with the given key. Here is what the tree looks like after deleting the single item 31 followed by the item 67.
Deleting item 19 puts the 56 temporarily on its spot and then sifts it down to trade with item 54, producing:
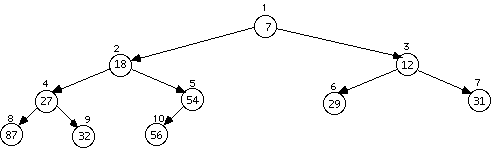
Deleting the item at the root (7) causes a substantial rearrangement as item 56 is placed in its spot and then sifted down the lesser of the child paths until it is a correct child again, producing:
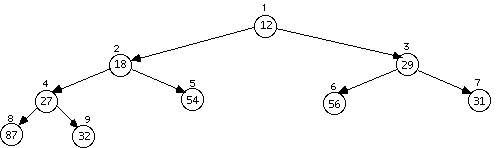
An attempt to delete something that is not there should not change the tree, but the programmer could require this to set some kind of error condition that could then be checked.
With this description complete, the following can be offered as a definition for the Heap ADT. Observe that it is somewhat more elaborate than the definition of the B-tree, as it allows for four kinds of traversals and in either direction.
DEFINITION MODULE Heaps;
(******************
Design by R. Sutcliffe copyright 1996
Modified 1996 10 16
This module provides a Heap ADT.
******************)
FROM DataADT IMPORT
KeyFieldType, DataType, ActionProc;
(* rename the imported types to the local ones. This makes things more generic and easier to change. *)
TYPE
ItemType = DataType;
KeyType = KeyFieldType;
TYPE
Heap;
HeapState = (allRight, empty, enheapFailed);
TraverseKind = (preOrder, inOrder, postOrder, rowOrder);
PROCEDURE Status (heap : Heap) : HeapState;
(* Pre : t is a valid initialized heap
Post : The State of the heap is returned *)
PROCEDURE Init (VAR heap : Heap);
(* Allocates memory for a new heap sets state to allRight *)
PROCEDURE Destroy (VAR heap : Heap);
(* disposes the whole heap *)
PROCEDURE Add (VAR heap : Heap; data : ItemType);
(* Pre : heap is a valid initialized Heap
Adds a new item to the heap. If successful sets state to allRight, else to enheapFailed *)
PROCEDURE Delete (VAR heap : Heap; key : KeyType);
(* Pre : heap is a valid initialized Heap
deletes an item whose key is defined equal to _key_ from the heap. If successful sets state to allRight; if heap was empty sets state to empty *)
PROCEDURE Search (heap : Heap; key : KeyType; VAR data : ItemType) : BOOLEAN;
(* Pre : heap is a valid initialized Heap
if found, returns TRUE and _data_ returns item at that point *)
PROCEDURE SetTraverseKind (heap : Heap; tKind : TraverseKind);
(* Pre : heap is a valid initialized Heap
The default is inorder *)
PROCEDURE ReverseTraverseDirection (heap : Heap);
(* Pre : heap is a valid initialized Heap
The default is forward, but this can be changed to and fro. The user has to keep track. *)
PROCEDURE Size (heap : Heap) : CARDINAL;
(* Pre : heap is a valid initialized Heap
Post: The number of data items in the heap is returned*)
PROCEDURE Traverse (heap : Heap; Proc : ActionProc);
(* Pre : heap is a valid initialized Heap
Post : the nodes are traversed inorder and Proc is performed on each data item. *)
END Heaps.