Programs depend on data input in order to properly express the solution to a problem. In the examples seen thus far in this text, programs have taken their data from:
These two styles, used alone, have in common that both the data employed and the results produces do not survive the run of the program. When the program is next run, the data must be obtained again (even if it is the same data, or only slightly changed), and the results cannot be fed forward to become the input for some other program. In order to work around these obstacles, a means of storing data outside programs is required. Files serve not only this purpose, but also provide a way of storing very large data collections, for which individual entry to every program would be impractical. Indeed, it is often the case in such instances that the data is the central theme to an entire symphony of programs operating on it, and that no one of the programs in the collection is nearly as important as the data itself.
A file resembles a book. Its structure (plot) is created in the mind of an author and it must be written (encoded) on some medium. Once this has been done, others can read it. However, in order to read it intelligibly, they must follow the structure created by the author.
A file is a source or a sink for a collection of data.
Just as data must be structured or arranged in such a way as to represent some real life problem, so also files must be structured (the plot, again) so as to represent the data they are intended to store. There are as many ways to do this as there are programmers, computers, operating systems, programs, and problems. The definition of a file has been expressed in a broad and general form for this very reason--the meaning must cover a lot of ground. In fact, by this definition, the batched data within a program and the data input interactively at a keyboard by the user of a program are both files--at least conceptually.
At the highest and most abstract level, a book can be thought of in terms of its plot, character and events. At a middle level, the book is perhaps structured by named chapters. On a more detailed level, the book is a collection of words on a page. That is, there are degrees of abstraction to the concept book as there are for many other commonly used ideas. This observation leads to the first classification of files, by the degree of their abstraction:
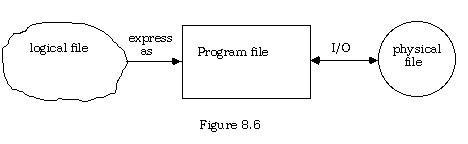
A logical file is an abstract structuring of data storage as viewed by the programmer and/or user of the program. This is the high level, or conceptual view of a file.
A program file is a specific data collection as seen and manipulated by a program. It is often (but not always) represented by a variable, perhaps of type "file." At this middle level of abstraction a file can be regarded as residing within the machine's memory, as existing only as long as the program that employs it is active.
A physical file is a recording of a logical file. This usually takes the form of a magnetic image on a disk or tape surface, in which form it exists independently of any particular program. The details of this recording provide the lowest level view of a file.
The distinction between the latter two levels of abstraction is not always maintained, and the term physical file is used by some for both the memory image and the external storage.
In order to write a useful program that employs files, some attention needs to be paid to all three levels of abstraction. The contents of the file must be decided on abstractly and conceptually; a program must be written to render the abstractions into a solution; and the resulting data must actually be recorded externally to the program so that it survives when the program terminates. Alternatively, an existing file may have to be read by a program, and this operation in turn can only be expressed if the original logical structure of the physical file is known.
The relationships among the three views of a file are expressed in figure 8.6 below. Observe that if the broadest possible view of a file is used, all input to and output from a program uses files.
Fortunately for programmers, the troublesome details of how files are to be physically stored can be left to the operating system, whose function it is to make such recordings, name them, keep track of them, ensure their integrity, and deliver them back to a program upon demand. This observation might seem to indicate that a simple and universal file handling module could serve as the interface between programs and operating systems.
Unfortunately there are many different operating systems, and widely differing views of what constitutes a simple program interface with any one of them. Thus, there have been many attempts to provide universal file handling interfaces, and these differ widely. Indeed, perhaps the most troublesome area for both the designers of a computing notation and for those who program using it is how to deal with input and output, as they are on the one hand essential to any substantial programming activity, and on the other closely tied to a particular system.
The problem for a language designer is the necessity to find common ground ahead of time for all possible external devices and operating systems so that I/O routines can be universally applicable. In Modula-2, this problem has been partially avoided by placing such matters outside the purvey of the language proper, and by assuming instead that any device needing communications links with a program will have these facilities supplied in a particular implementation by appropriate library modules.
This results in the Modula-2 notation itself being small and versatile, but causes somewhat more work for the programmer, who often had a large number of library routines to keep straight--especially if using more than one version--for then there was no guarantee that such libraries would correspond.
In spite of this deliberate lack of pre-specification by Wirth (he required no particular I/O routines or modules, and only made a few suggestions of modules he had found generally useful), much can still be said about such functions. Although operating systems differ widely, there are many things that they do have in common. Moreover, there are not many kinds of logical file in common use, even though the recordings of such files may be very different. As a result, many vendors of Modula-2 products produced very similar libraries for I/O and to some extent, this tended to create a de facto or marketplace standard. One section of this chapter is devoted to outlining the most common I/O and file handling routines used by commercial vendors in the years when no official standards existed.
Even the ubiquitous classical high level modules InOut and RealInOut have many variations however, and lower level modules often have more differences than similarities between implementations. This was one of the major reasons for convening a working group (WG13) of the International Standards Organization (ISO) in April of 1987 to produce a standard definition of both Modula-2 and its libraries. This standard will be the focus for most of the rest of this chapter and will be used subsequently when a sample solution happens to call for the use of files.
Before looking at the specifics of handling the program/logical file communication, however, some additional attention needs to be paid to the logical view of data storage.
Sequences have been discussed before in sections 3.8, (arithmetic sequences) and section 4.9 (geometric sequences.) The concept of a statement sequence is also important in Modula-2. In general, a sequence is any collection of entities that can be numbered in some well-defined way using the cardinal numbers 1, 2, 3, 4, 5, ....
More Mathematically,
A sequence is a function from the positive whole numbers into some other collection of objects.
Here are some examples of sequences with commas between the elements for clarity:
I, n, ,t, h, e, , b, e, g, i, n, n, i, n, g, , G, o, d, ...
1, 3, 5, 7, 9, ...
1, 4, 9, 16, 25, 36, ...
1, 1, 2, 3, 5, 8, 13, ...
1, 1.1, 2, 2.2, 3, 3.3, 4, 4.4, ...
From the point of view of computer input and output, the definition above is specialized as follows:
A stream is a sequence of data items of the same type.
All but the last of the sequences above could be streams if the items in them are considered as data being manipulated by a program.
In general, streams all have some properties in common. These are:
1. The number of elements in the stream is not known ahead of time (i.e. by the writer of the stream handling module before the data type is ever used in a program). In an actual instance of a particular stream, there is (eventually) a finite length associated with it that may be possible to compute.
2. A stream has an origin and a destination, which are also not necessarily known ahead of time (again, when the stream handling module is designed), but which may default to some standard place or device. It is usually possible to change these default connections to something else.
3. It is possible to write only at the end of a stream (i.e. writing is always appending), and the only other way to modify a stream is to delete it entirely.
4. Any element of a stream can be read, provided that reading starts at the beginning of the stream and proceeds through the elements one at a time in order until the desired one is reached (sequential reading).
5. For some specialized streams, it may be possible to maintain a window or a pointer to the last element that was read so that the next one can be read at a later time without starting from the beginning again. If this is done, the position pointer is usually advanced one place by the very act of performing the read operation.
6. A stream has a mode. It is either being read from or written to at any given time. Some streams may have only one possible mode, and others may allow procedures to operate on their status to alter the mode.
As can readily be seen, the high level modules STextIO, SWholeIO, SRealIO, and SLongIO operate on streams. They employ a variety of Read and Write operations for the sake of convenience, but the actual streams being manipulated in this case consist of text characters, regardless of the formal type of data being read or written.
That is, procedures like WriteString and WriteCard both write characters to the output device, and both ReadChar and ReadInt read characters. It is the further duty of SWholeIO and SRealIO to then arrange for another module to convert the character strings to and from the correct type of program data (perhaps an integer), but that is a separate consideration.
A stream whose items are of the character type is called a text stream (or a legible stream.)
On the other hand, an input or output stream could be thought of on a lower level of abstraction as a sequence of binary items, rather than as a sequence of text characters. Indeed, not all streams are best abstracted as text; a binary abstraction might be the only practical way to think of a some streams.
A stream whose elements are thought of as binary digits is called a binary stream (or a raw stream.)
Implicitly, there are exactly two default streams used by STextIO, SWholeIO, SRealIO, and SLongIO--one for input, and one for output. However, it is also possible to have a program to maintain several (other) streams too, with various origins, destinations, modes, lengths, and position pointers.
The analogy of observing flowing water (a real stream) is quite apt. It is helpful to think of data streams as being contained by their banks and as consisting of a flow passing by some program aperture, and into which new data can be placed, or from which previously placed items can be plucked--all under program control via routines imported from stream management modules.
The ISO committee found it useful to assume that file management was a low level function that could be different in every implementation, and to standardize instead the containment (stream bed) abstraction at a somewhat higher level than that of file management. This abstraction could also be thought of as the connection mechanism joining logical files to physical files.
A channel is an abstract medium through which a stream flows.
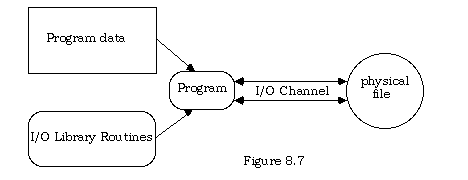
The role of a stream managing module is analogous to that of a plumber, whose task it is to connect and maintain the pipes or channels to the various sources and sinks in the system. Using such a facility, a program may be connected to one or more of a variety of input streams and one or more of a variety of output streams at a given time. Figure 8.7 illustrates:
Having examined flows of data, consider now where the data flows lead to and from. On one end of a data stream is the program. It is tempting to say that the other end is some physical device such as a disk drive, or a printer, but it is more accurate to view the destination as a physical file, and not as a location.
The location of the physical file could be a recipe box, a disk drive, or the main memory of the computing device. The program deals with the file only on the logical level, and in practice, may do so just by writing to the stream in an appropriately connected channel. The logical file and the stream are not identical, though the two do share in common that they only exist as the creatures of some running program, and are therefore both more abstract than the physical file. In fact, a file may be organized by a program as the recording of a stream, or it may not be--depending on the way that information is accessed in the file. To distinguish, a new classification scheme for files is necessary:
A file that is organized as a stream, with writing allowed only at the end, is called a sequential file. If the underlying type of data in the stream is character, it is further known as a text file.
On the other hand, a file might be logically organized more like an array. The elements of an array are numbered consecutively, and may be read consecutively. However, and one element can be accessed by its own number in the sequence at any time (e.g. element [1243]) without reading all the ones that came before it first.
A file that may have any of the data elements read or written directly by some indexing scheme without having to start at the beginning is called a random-access file.
If the elements making up a random access file are, say, integers, then they must not be stored as text, for in that form different integers take a different amount of storage. For instance, the integer 123 would be expressed as the character stream "1", "2", "3" and take three storage positions in a text file, whereas the integer -46553 would require six storage positions for its characters. In the memory of a computer, every integer takes the same amount of room, as a given integer storage location must be able to hold any valid integer value. This is why the read/write memory is called RAM or random access memory. The same storage considerations hold for a random access file. Since there can only be a certain amount of room in the physical file for a given element, it follows that each numbered element of a random access file must be the same size as every other element.
Thus, a random-access file-managing module may be similar to that for sequential files, but it must also have a means of calculating the correct position in the file at which to read or write a given data item. What one would expect to find in a well-developed library suite is modules that impose one of these models on I/O, perhaps overlaid on top of some lower level ones that are in turn manage the connections between programs and the physical files through the operating system. The specifics of handling files using the random access model will be covered in chapter 9; sequential file models are of more immediate interest.
Consider first the stream model for a file. Until now, this text has used only the high level modules STextIO, SWholeIO, SRealIO, and SLongIO or InOut and RealInOut to connect to input and output streams. These connections could be diverted from their default source and sink via the non-standard procedures OpenInput and OpenOutput (where available). While there is a certain convenience to using these, there are times when one would like the redirection of I/O to be handled automatically by the program, without the intervention of the operator at the console to answer the prompts (or fill in dialogue boxes) as required by these two high level procedures. Moreover, these procedures allow only sequential files, and they do not allow one to append to a file. Furthermore, they are not a part of the ISO standard, and therefore cannot be counted on to be present at all.
Suppose, for instance, that one wanted to collect data from the keyboard and store it into a disk file. Then later, (in this, or another program) one wanted to examine that disk file and manipulate the stored information further. All this is to be done without any prompts being supplied or any file names being requested from the keyboard; those are to be contained in the program itself. To achieve this, one must pursue library routines at a lower level than the simple I/O modules used thus far.
In general, one performs operations on sequential files with these steps (assuming that appropriate imports have been made):
1. Declare a file variable to logically identify the file within the program
or declare a channel variable to identify the logical/physical connection
2. Use the file's actual name (a string) to look it up (or create it) on the external device--say, a disk
3. Identify the logical file variable with the actual disk file (open the file)
4. Connect a program I/O stream to the previously opened file,
5. Read from or write to the stream, and hence the logical, and so the physical file
6. When finished, disconnect the stream from the program and
7. Close the file, ensuring that the data is secure on the disk.
Depending on the version of Modula-2 involved, there may be from one to five modules in the library that contain the functions necessary to implement this model. In classical versions, one was usually called Files (or FileSystem) and contained the data type FILE (or File), together with the functions to create new files on a disk (or other device), open them for I/O by identifying them with a logical file name, close them when finished, rename, or delete existing files, and handle errors. Such a module is concerned with the manipulation of the physical data on the disk or other storage medium. It usually has only rudimentary read/write procedures for text material and its functions may be specialized into two or more smaller modules each of which handles a different aspect of these tasks.
On the other hand, the functions for establishing a stream of text characters, connecting this to the already opened file, and then performing the actual read/write operations might also be in Files, (in older versions) or they might be situated in a separate module, variously called Texts, TextIO or Streams (Wirth suggested the last of these, but did not require it). This second module, whatever its name, manipulates streams through the logical stream name within the program, and its activities affect the contents of the physical (disk) files only indirectly through the connections that the program has established between the stream and the logical file, and between this and the physical file. Note that in the fullest elaboration of this scheme, the logical stream is an entirely different entity from the logical file, which in turn is a different entity from the physical file.
Some additional associated modules may be provided to ease the entering (and checking for validity) of valid file names, may specialize the directory lookup step, or may provide for separate encapsulation of the procedures for numeric I/O to files, as opposed to text I/O. One must consult the documentation for the specific implementation on this point, as the details vary widely.
Some early implementations actually used all the ideas presented so far and employed two data types to do so--FILE and TEXT (or STREAM). Many other classical versions of Modula-2 took a higher-level view of the matter, and employed only a single data type File that did double duty as both stream and file, for opening a file and for making the necessary connections between the physical file and the stream, or otherwise combined some of the distinct tasks on the list above into single steps.
ISO standard Modula-2 also takes a high level view, but hides the concept of a logical file altogether, and uses the abstraction of a Channel as the means to connect program data with physical files. Thus, in the ISO model, one has:
There might also be a low level housekeeping module called Files or Filer or FileSystem on top of which the specific models for different kinds of channel are built. This module and its contents are deliberately not standardized, as it is here that the differences between operating systems must be expressed. Thus, portable programs should avoid calling on routines from such a module.